
I’ve been writing—a lot—about attribution lately, so let’s do the trendy thing in marketing blog posts lately and ask ChatGPT what marketing attribution is!
When you prompt with “what is marketing attribution,” the first paragraph the software returns is:
“Marketing attribution refers to the process of assigning credit to specific touchpoints in the customer journey that ultimately led to a conversion. The goal of attribution is to understand the role that each marketing channel and touchpoint played in the customer’s decision-making process and to determine the most effective marketing strategies.”
OK, that’s not exactly how I’d word it, but it’s an acceptable answer for an overall definition of marketing attribution.
However, it immediately goes into the following second paragraph:
“There are several attribution models, including last-click attribution, first-click attribution, linear attribution, and time decay attribution, among others. Each model assigns different levels of credit to various touchpoints in the customer journey, and different models may produce different results for a given scenario.”
Wait. What? We weren’t talking about modeling at all, and now this is a critical item to discuss when summarizing the topic? That doesn’t make much sense.
I joked in a previous article about how marketing blog articles about attribution tend to be structured as “Attribution exists! There’s…something you need to do? Also, models!” As such, it’s unsurprising that ChatGPT would take that perspective; machine learning can only regurgitate content it already knows. However, if we do a deep dive into how we got into this mess, we can also find a saner path forward: Use what we know in 2023 versus what we came up with decades ago.
Marketing Memes Can Skew Our Perception
When we think of marketing operations and memes, we tend to think in more modern terms, but if we think of memes more in the classical sense, you’ll notice more long-standing ideas than you’d expect. One of my least favorite marketing memes, for example, is that you should send your emails out at 11 a.m. on a Tuesday to see the best results. But where did this come from?
Well, it turns out it’s rather old: an early email newsletter sent to email marketers published a tip in 1997 saying that the best time to send mass emails was 11 a.m. on Tuesdays. This was not backed with any citations or research analysis; this statement was just something that passed the vibe check back then. Unfortunately, as content for digital marketers proliferated over the next several years, this idea was taken and carried forward in new publications (without citation). Somewhere along the way, this idea became “accepted wisdom” as a result.
Savvier marketers will know this is a meme and not something to take as the undisputed truth, but if I take a look at my own email inbox for 2022’s messages, you’ll notice that the volume of email still tends to cluster around Tuesday mornings:
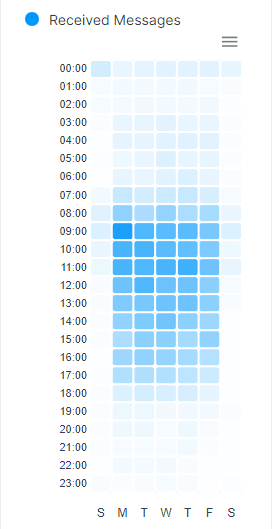
This is due to more recent studies also “confirming” that emails get more engagement on Tuesday mornings than at any other time. There’s one critical thing missing from these more contemporary studies, though: it has been the accepted “common wisdom” that sending on Tuesday mornings gets the most engagement, and we know from multiple studies (2013, 2022) that most emails get opened within the first few hours of them being sent.
As such, it’s not surprising that even modern studies would say “send time optimization” is on Tuesday mornings—because statistically, more emails are being sent on Tuesday mornings due to this marketing meme. There’s no way to have a more objective view because the existing belief that this is the “best time” skews the dataset.
The 2023 answer to “what time should I send my emails?” is calculated very differently than 25 years ago. Even if you believe that your audience is most likely to engage at 11 a.m. on a Tuesday, you’ll have data in the aggregate to look at over time. You’ll be able to validate whether users actually open emails at that time—or if they best respond at other times. After all, if everyone is emailing at 11 a.m., you will get lost in everyone else’s messaging. This is the power that modern analytics can provide: If you have ample data at scale, it’s straightforward to use big data to get more accurate insights—and need fewer “best guesses.”
How Did We Get the “Attribution Model” Meme?
When you take a deeper look at marketing “best practices,” you’ll find more and more of these memes: unverified ideas that make sense at the surface but tend to fall apart with any analysis tailored to your organization. Another commonly misunderstood meme is attribution modeling. How did we get to a point where even ChatGPT thinks this is part of every marketing attribution conversation, and how can we have a 2023 understanding of what to do instead of relying on a model?
First, let’s take a step back. I personally believe that marketing automation platforms, like Marketo or Eloqua, are the best tools for the job when you’re trying to measure a customer journey. For example, I’d argue that lifecycle measurement is the backbone of Marketo. However, that’s not a universal position. I know of a company that decided to handle all of its lead lifecycle and customer journey measurement… inside Google Analytics. They invested significantly in using the platform to track all sorts of online and offline journeys, then used that data to run a basic attribution model based on Google’s technology.
If you’ve worked in digital marketing for a while, you’ll realize a big problem in that scenario: It’s dependent on pushing all sorts of non-Google Analytics data into the platform, reworking that data so it fits within Google Analytics’ user, session, and event data model, and then reconciling the online and offline data to have GA create an attribution model. It’s hardly ideal and involves a lot of manual or semi-automatic data transfer to get basic information.
This company’s decision always struck me as odd. The money they invested in this custom solution would have covered purchasing a marketing automation platform with change to spare. However, there’s a particular method to this madness—because Google Analytics provides attribution models, and they were familiar with those already, they used GA as a basis to work with. Why would Google Analytics, a web analytics tool, have attribution models, anyway?
In the earliest days of web analytics, information on your website’s performance was calculated using raw server logs. In other words, the basic information your website records when someone connects to the machine would be written into a text or database file; web analytics software like AWStats would then process that data locally. This is why metrics like “unique visitors” and “pageviews” dominated so much of early web analytics—they’re far more straightforward to calculate from a log than other types of data. As the early web matured, another data point also needed to be calculated: performance on advertisements such as banner ads and PPC ads on search engines. Log tools couldn’t handle this kind of measurement by default, so several new technologies emerged to track those advertisements in particular.
One of these newer technologies, Urchin, was also based on reviewing log data—except the platform would record additional information from the web page visited after the URL and break it out into separate reports. You’re probably familiar with the result: the Urchin Tracking Module, or UTM, parameter. The reason Google chose to acquire Urchin in 2005 was that they saw the platform as a gap between their business of selling display and search ads and showing their efficacy. As a result, the subsequent development of what’s now known today as Google Analytics was driven by this model: How do we report on ad-driven data so customers buy more ads?
Google started by abstracting away the need to read your logs, instead recording all data on their end, then focused on tools and visualizations that would better demonstrate how digital advertising impacted analytics. However, if you’ve done any work with Google Analytics, you’re probably aware of its limitations. For example, if you have a pattern like:
- Net new person comes to your website after seeing a targeted display ad
- New person looks around at several pages, then closes their session
- New person comes back three days later and fills out a Demo Request form, triggering an ad conversion pixel
In 2005, there really was no good way to explain this behavior in analytics—even though it’s pretty common, even today. As a result, we saw the development of ad attribution models: a tool that could look at the overall log files of a person’s sessions and start to make educated guesses on how that ad impacted later traffic.
Since it’s quite common to have a person visit a website multiple times prior to conversion, these models would try to abstract the tracking information it had—even when someone had no tracking information aside from one webpage hit—to provide information back to the ad purchaser. After all, no one would buy ads they couldn’t prove were converting in some form.
This is also why various models were introduced to track conversions: even in instances where information would be incomplete or not always reconcile 1:1 with previous sessions, you could always see an ad conversion in a last-touch model or similar. The models are ways of shifting the data to tell a story and explain why you should continue buying more online advertisements. When the idea of modeling overall marketing efforts into attribution came about, it was straightforward to build based on what had already been in other types of software: 2005’s ad attribution modeling technology.
It’s not 2005 any longer, though.
If we were to look at this problem from a 2023 perspective, we now have the ability to use data at scale to figure out an exact series of steps someone took. We no longer have to rely on models as shorthands to understand behaviors like someone leaving a website and returning; we can instead use modern signals to tell a detailed story—think of something similar to the Marketo Activity Log that can be pulled across all behaviors. Additionally, other perceived benefits of attribution models fall apart when we look at them from modern viewpoints.
Liberating Your Data from Attribution Models
One common reason I hear for weighing an attribution model is the timing or urgency of a campaign initiative. If you send late-stage content to someone as a “closer” to convert, you may be tempted to weigh that campaign more heavily as influencing a sale. However, this can cause other problems.
There can be a belief that this particular campaign is a campaign that “closes” people or has enough impact to be disproportionally weighted. This is a dangerous assumption that can be made by anyone working with a prospect—whether that’s marketing, sales, customer success, or another department. In reality, there’s often a combination of reasons that moves someone towards a purchase, and they may or may not even be a tangible reason you could give credit to.
For example, I sometimes buy consumer goods based solely on the design and aesthetics of their packaging. My mind (potentially incorrectly) assumes a company that can afford better-designed packaging can likely afford to spend more on product R&D and quality, too. Maybe I saw an advertisement that informed me about the product, but when I went to purchase the product on the shelf at a store, I was more swayed by the packaging. So do you credit the advertising or the packaging?
In this case, like many cases, you can’t measure the more arbitrary reason someone moves forward with a sale—but you can measure the advertisement’s performance as a touchpoint that assisted the purchase. Therefore, rather than worry about weighing this point as “more important” than others, ask the better question: How often does this campaign influence a sale?
The Modern Approach to Attribution Modeling
Marketers sometimes get caught up in the narrative story of an exact conversion path, and thus conversion points that can’t be seen can become stumbling blocks. A good way to think about this instead would be to think about attribution like an algebraic equation.
(Content warning: algebra.)
Imagine 2X + Y = 10, where 10 equals a sale. There are many ways where X and Y can be different values and still add up to 10: for example, both 2 * 2 + 6 = 10 and 2 * 3 + 4 = 10.
This is much like the real world, where we know there can be a wide variety and number of touchpoint combinations between your organization’s sales, marketing, and customer success departments and a prospect. As a result, rather than focus on the rigidity of a model holding “importance” on a single touchpoint, you can focus on the common patterns of touchpoints that result in success. Likewise, you may only know part of the combination of touchpoints that influence a sale: Say you only know X or Y in the equation of what makes someone convert. That’s a more realistic situation, but if you are unduly weighing X, so it’s 4X + Y = 10, you’ve lost any nuance in better understanding Y.
When you abstract away from needing exact weights of touchpoints on conversion paths, you also gain the benefit of giving those touchpoints more emphasis within a point in contextual time rather than a point in a sequence. If we’re still considering a piece of late-stage content, we may start early on by understanding this campaign as a point in a sequence: We know this is the “last” piece of content that results in a conversion. However, if we weigh that sequence, we miss the ability to understand our late-stage content campaign better.
If we think about this campaign, it’s trying to meet prospects at a time in context: for example, it may target people in a “Sales Qualified Lead” stage. If we look at this campaign from the point of view of “Sales Qualified Leads who receive this piece close,” we can start to ask several follow-up questions the weighted attribution model can’t solve:
- What happens if this content is consumed at an earlier stage, like Sales Accepted Lead?
- What situations can occur where someone consumes this content, then consumes other content after, but ultimately converts as a sale?
- What cohort of campaigns do people most commonly participate in that help this campaign be successful?
- Can we validate that this content converts well for Sales Qualified Leads, regardless of the order of touchpoints?
Rather than worrying about the relative impacts of touchpoints to each other, modern marketers can take advantage of the volume of data to allow any measurable touchpoint to be gathered and analyzed across the customer’s journey. This allows the data to describe what campaigns are the most effective and in what contexts rather than having the marketer prescribe an arbitrary amount of importance. When even ChatGPT is trying to tell you about “last-click attribution,” it’s understandable that you may think this is something to consider when looking at attribution software. It’s not—if you’re living in the year 2023.


